指令和指令集
字节码、class文件、指令集的关系
class文件(二进制)和字节码(十六进制)的关系
class文件
经过编译器编译后的文件(如javac),一个class文件代表一个类或者接口;
是由字节码组成的,主要存储的是字节码,字节码是访问jvm的重要指令
文件本身是2进制,对应的是16进制的数。
字节码
包括
操作码(Opcode)和操作数:操作码是一个字节如果方法不是抽象的,也不是本地方法,方法的Java代码就会被编译器编译成字节码,存放在method_info结构的Code属性中

如图:操作码为B2,助记符为助记符是getstatic。它的操作数是0x0002,代表常量池里的第二个常量。
操作数栈和局部变量表只存放数据的值, 并不记录数据类型。结果就是:指令必须知道自己在操作什么类型的数据。
这一点也直接反映在了操作码的助记符上。
例如,iadd指令:对int值进行加法操作; dstore指令:把操作数栈顶的double值弹出,存储到局部变量表中; areturn:从方法中返回引用值。
助记符
如果某类指令可以操作不同类型的变量,则助记符的第一个字母表示变量类型。助记符首字母和变量类型的对应关系如下:
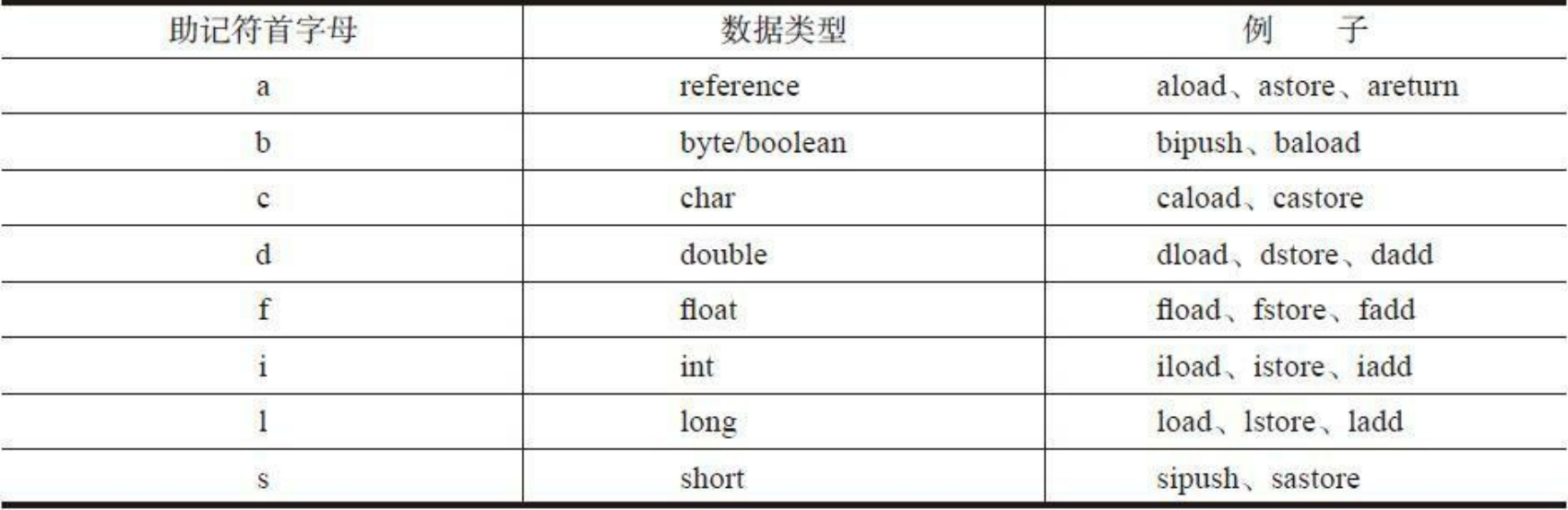
指令分类
Java虚拟机规范把已经定义的205条指令按用途分成了11类, 分别是:
- 常量(constants)指令
- 加载(loads)指令
- 存储(stores)指令
- 操作数栈(stack)指令
- 数学(math)指令
- 转换(conversions)指令
- 比较(comparisons)指令
- 控制(control)指令
- 引用(references)指令
- 扩展(extended)指令
- 保留(reserved)指令:
- 操作码:202(0xCA),助记符:breakpoint,用于调试器的断点调试
- 254(0xFE),助记符:impdep1
- 266(0xFF),助记符:impdep2
- 这三条指令不允许出现在class文件中
本章将要实现的指令涉及11类中的9类
JVM执行引擎
执行引擎是Java虚拟机四大组成部分中一个核心组成(另外三个分别是类加载器子系统、运行时数据区、垃圾回收器),
Java虚拟机的执行引擎主要是用来执行Java字节码。
它有两种主要执行方式:通过字节码解释器执行,通过即时编译器执行
解释和编译
在了解字节码解释器和即使编译器之前,需要先了解解释和编译
- 解释是将代码逐行或逐条指令地转换为机器代码并立即执行的方式,适合实现跨平台性。
- 编译是将整个程序或代码块翻译成机器代码的方式,生成的机器代码可反复执行,通常更快,但不具备跨平台性。
字节码解释器
字节码解释器将逐条解释执行Java字节码指令。这意味着它会逐个读取字节码文件中的指令,并根据每个指令执行相应的操作。虽然解释执行相对较慢。
逐行解释和执行代码。它会逐行读取源代码或字节码,将每一行翻译成计算机指令,然后立即执行该指令。
因此具有平台无关性,因为字节码可以在不同的平台上运行。
即时编译器(Just-In-Time Compiler,JIT)
即时编译器将字节码编译成本地机器代码,然后执行本地代码。
这种方式更快,因为它避免了字节码解释的过程,但编译需要一些时间。
即时编译器通常会选择性地编译某些热点代码路径,以提高性能。
解释器规范
Java虚拟机规范的2.11节介绍了Java虚拟机解释器的大致逻辑,如下所示:
do {
atomically calculate pc and fetch opcode at pc;
if (operands) fetch operands;
execute the action for the opcode;
} while (there is more to do);
- 从当前程序计数器(Program Counter,通常简称为 PC)中获取当前要执行的字节码指令的地址。
- 从该地址获取字节码指令的操作码(opcode),并执行该操作码对应的操作。
- 如果指令需要操作数(operands),则获取操作数。
- 执行指令对应的操作。
- 更新 PC,以便继续执行下一条字节码指令。
- 循环执行上述步骤,直到没有更多的指令需要执行。
每次循环都包含三个部分:计算pc、指令解码、指令执行
可以把这个逻辑用Go语言写成一个for循环,里面是个大大的switch-case语句。但这样的话,代码的可读性将非常差。
所以采用另外一种方式:把指令抽象成接口,解码和执行逻辑写在具体的指令实现中。
这样编写出的解释器就和Java虚拟机规范里的伪代码一样简单,伪代码如下:
for {
pc := calculatePC()
opcode := bytecode[pc]
inst := createInst(opcode)
inst.fetchOperands(bytecode)
inst.execute()
}
指令和指令解码
本节先定义指令接口,然后定义一个结构体用来辅助指令解码
Instruction接口
为了便于管理,把每种指令的源文件都放在各自的包里,所有指令都共用的代码则放在base包里。
因此instructions目录下会有如下10个子目录:
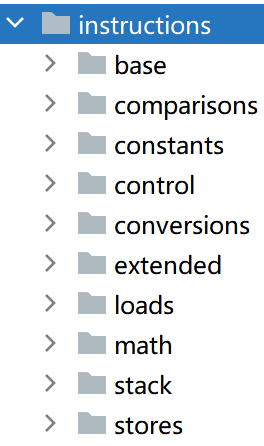
base目录下创建instruction.go文件,在其中定义Instruction接口,代码如下:
type Instruction interface {
FetchOperands(reader *BytecodeReader)
Execute(frame *rtda.Frame)
}
FetchOperands()方法从字节码中提取操作数,Execute()方法执行指令逻辑。
有很多指令的操作数都是类似的。为了避免重复代码,按照操作数类型定义一些结构体,并实现FetchOperands()方 法。
无操作数指令
在instruction.go文件中定义NoOperandsInstruction结构体,代码如下:
type NoOperandsInstruction struct {}
NoOperandsInstruction表示没有操作数的指令,所以没有定义 任何字段。FetchOperands()方法自然也是空空如也,什么也不用 读,代码如下:
func (self *NoOperandsInstruction) FetchOperands(reader *BytecodeReader) {
// nothing to do
}
跳转指令
定义BranchInstruction结构体,代码如下:
type BranchInstruction struct {
//偏移量
Offset int
}
BranchInstruction表示跳转指令,Offset字段存放跳转偏移量。
FetchOperands()方法从字节码中读取一个uint16整数,转成int后赋给Offset字段。代码如下:
func (self *BranchInstruction) FetchOperands(reader *BytecodeReader) {
self.Offset = int(reader.ReadInt16())
}
存储和加载指令
存储和加载类指令需要根据索引存取局部变量表,索引由单字节操作数给出。把这类指令抽象成Index8Instruction结构体,定义Index8Instruction结构体,代码如下:
type Index8Instruction struct {
//索引
Index uint
}
FetchOperands()方法从字节码中读取一个int8整数,转成uint后赋给Index字段。代码如下:
func (self *Index8Instruction) FetchOperands(reader *BytecodeReader) {
self.Index = uint(reader.ReadUint8())
}
访问常量池的指令
有一些指令需要访问运行时常量池,常量池索引由两字节操作数给出,用Index字段表示常量池索引。定义Index16Instruction结构体,代码如下:
type Index16Instruction struct {
Index uint
}
FetchOperands()方法从字节码中读取一个 uint16整数,转成uint后赋给Index字段。代码如下
func (self *Index16Instruction) FetchOperands(reader *BytecodeReader) {
self.Index = uint(reader.ReadUint16())
}
指令接口和“抽象”指令定义好了,下面来看BytecodeReader结构体
BytecodeReader结构体
base目录下创建bytecode_reader.go文件,在 其中定义BytecodeReader结构体
type BytecodeReader struct {
code []byte // bytecodes
pc int
}
code字段存放字节码,pc字段记录读取到了哪个字节。
为了避免每次解码指令都新创建一个BytecodeReader实例,给它定义一个 Reset()方法,代码如下:
func (self *BytecodeReader) Reset(code []byte, pc int) {
self.code = code
self.pc = pc
}
面实现一系列的Read()方法。首先是最简单的ReadUint8()方法,代码如下:
func (self *BytecodeReader) ReadUint8() uint8 {
i := self.code[self.pc]
self.pc++
return i
}
- 从
self.code字节切片中的self.pc位置读取一个字节(8 位)的整数值。 - 然后将
self.pc的值增加1,以便下次读取下一个字节。 - 最后,返回读取的字节作为无符号 8 位整数
ReadInt8()方法调用ReadUint8(),然后把读取到的值转成int8 返回,代码如下:
func (self *BytecodeReader) ReadInt8() int8 {
return int8(self.ReadUint8())
}
ReadUint16()连续读取两字节
func (self *BytecodeReader) ReadUint16() uint16 {
byte1 := uint16(self.ReadUint8())
byte2 := uint16(self.ReadUint8())
return (byte1 << 8) | byte2
}
ReadInt16()方法调用ReadUint16(),然后把读取到的值转成 int16返回,代码如下:
func (self *BytecodeReader) ReadInt16() int16 {
return int16(self.ReadUint16())
}
ReadInt32()方法连续读取4字节,代码如下:
func (self *BytecodeReader) ReadInt32() int32 {
byte1 := int32(self.ReadUint8())
byte2 := int32(self.ReadUint8())
byte3 := int32(self.ReadUint8())
byte4 := int32(self.ReadUint8())
return (byte1 << 24) | (byte2 << 16) | (byte3 << 8) | byte4
}
在接下来的小节中,将按照分类依次实现约150条指令,占整个指令集的3/4